Deep Learning for Time Series
From Ising Models to Recurrent Neural Networks
Where We Are
We have been building a toolkit for modeling dynamical systems from data:
ODE discretization: $x_{k+1} = f(x_k)$
SVD/POD for spatial modes
DMD for linear dynamics
SINDy for sparse equations
What if the dynamics are too complex for a sparse model?
Can we learn $f$ directly from data using neural networks?
The Recurrence Idea
Every time-stepping scheme is an autoregressive model:
Part I: Physics Roots
The Ising Model, Hopfield Networks, and Boltzmann Machines
How statistical mechanics inspired the first neural network architectures
The Ising Model (Lenz 1920, Ising 1925)
A model from statistical mechanics: a 2D grid of spins, each either "up" $(+1)$ or "down" $(-1)$. Neighboring spins want to align. The model was designed to explain ferromagnetism: how local interactions produce global order.
$s_i \in \{-1, +1\}$ = spin at site $i$
$J > 0$ = coupling (scalar); favors aligned neighbors
$h$ = external magnetic field (scalar)
$\langle i,j \rangle$ = nearest-neighbor pairs only
At high temperature $T$: thermal noise dominates, random spins
At low temperature: energy dominates, aligned spins
At $T_c \approx 2.27 J/k_B$: phase transition!
Ising Model: The Algorithm
The Metropolis-Hastings algorithm simulates the Ising model at temperature $T$:
For each spin $s_i$ in random order:
1. Compute energy change if we flip it:
$\quad \Delta E = 2 J \, s_i \sum_{j \in \text{neighbors}} s_j$
2. If $\Delta E \leq 0$: flip (lower energy)
3. If $\Delta E > 0$: flip with probability $e^{-\Delta E / T}$
import numpy as np
def ising_step(grid, T, J=1.0):
N = grid.shape[0]
for _ in range(N * N):
i, j = np.random.randint(N, size=2)
s = grid[i, j]
# Sum of 4 nearest neighbors
neighbors = (grid[(i-1)%N, j] +
grid[(i+1)%N, j] +
grid[i, (j-1)%N] +
grid[i, (j+1)%N])
dE = 2 * J * s * neighbors
if dE <= 0 or np.random.rand() < np.exp(-dE / T):
grid[i, j] = -s
return gridFrom Spins to Neurons: Hopfield Networks (1982)
John Hopfield's insight: replace the Ising lattice with a fully connected network. Instead of nearest-neighbor coupling, every neuron connects to every other. The energy landscape has local minima that serve as stored memories.
Same energy as Ising, but with all-to-all learned weights $W_{ij}$ instead of uniform nearest-neighbor coupling $J$.

John Hopfield

Geoffrey Hinton
Nobel Prize in Physics 2024
How Hopfield Networks Work
The network operates as an associative memory: given a corrupted input, it recovers the closest stored pattern.
$s_i \in \{-1, +1\}$: neuron states (like pixel values in an image)
$W_{ij}$: connection weights (computed from training data)
Patterns $\xi^\mu$: binary images we want to store
$W_{ij} = \frac{1}{N} \sum_{\mu=1}^{M} \xi_i^\mu \xi_j^\mu$
(This is like an autocorrelation: neurons that co-activate get stronger connections)
$s_i \leftarrow \text{sign}\!\left(\sum_j W_{ij} s_j\right)$
Each update decreases energy $\Rightarrow$ converges to nearest minimum = nearest stored pattern
Hopfield: Capacity and Limitations
At most $\sim 0.138 N$ patterns for $N$ neurons.
Beyond this: spin-glass phase with spurious attractors (false memories).
- Low capacity: only $O(N)$ patterns
- Binary states only ($\pm 1$)
- Spurious attractors (mixture states, reversed patterns)
- No hidden representation
1. First architecture where physics principles (energy minimization) directly defined computation
2. The design logic generalizes: define an energy, let the system minimize it
3. Direct mathematical ancestor of transformers (next slide)
Research Connection: Modern Hopfield $\rightarrow$ Transformers
Ramsauer et al. (2021) showed that with continuous states and a log-sum-exp energy, the Hopfield update rule becomes:
Query state $\xi$, stored patterns $X$
Inverse temperature $\beta$
Storage: $\exp(O(d))$ patterns
Query $Q$, Keys $K$, Values $V$
$\beta = 1/\sqrt{d_k}$
$\text{softmax}(QK^T\!/\sqrt{d_k}) \cdot V$
Boltzmann Machines: Adding Stochasticity
Geoffrey Hinton and Terrence Sejnowski (1985) extended Hopfield networks with two ingredients:
Instead of deterministic $s_i = \text{sign}(h_i)$, flip with probability:
$$P(s_i = 1) = \sigma\!\left(\frac{h_i}{T}\right) = \frac{1}{1 + e^{-h_i/T}}$$ This lets the network escape local minima (like simulated annealing).
Split neurons into:
Visible $v$ = observed data (e.g., time series windows, sensor readings, image pixels)
Hidden $h$ = latent features the model discovers (temporal patterns, modes)
Boltzmann Machines: The Math
A Restricted Boltzmann Machine (RBM) has no connections within the same layer (bipartite graph):
Images: $v$ = 784 pixels (MNIST). RBM learns digit-like patterns.
Time series: $v$ = a window of $T$ observations $[x_t, \ldots, x_{t+T}]$. RBM learns temporal motifs and transition probabilities.
$P(h_j = 1 | v) = \sigma(b_j + \sum_i W_{ij} v_i)$
This makes sampling efficient (block Gibbs).
Training Boltzmann Machines
Goal: maximize the probability the model assigns to real data. The gradient has a beautiful structure:
Clamp $v$ to real data. Sample $h$ from $P(h|v)$.
Measures correlations in real data.
Sample from full model $P(v,h)$. Requires MCMC to equilibrium.
Contrastive Divergence (Hinton 2002): just 1 Gibbs step!
The Intellectual Lineage
Physics-inspired designs gave birth to modern deep learning:
Hopfield (1982)
Energy minimization
Associative memory
$\downarrow$
Modern Hopfield
$\rightarrow$ Transformers
Boltzmann (1985)
Gibbs distribution
Generative model
$\downarrow$
Pretraining
$\rightarrow$ VAEs, GANs, Diffusion
Ising (1920)
Phase transitions
Statistical mechanics
$\downarrow$
Energy-based learning
$\rightarrow$ Unifying framework
Part II: Recurrent Neural Networks
Learning dynamics in a hidden state space
The RNN Architecture
Instead of modeling $x_{k+1} = f(x_k)$ in the observable space, introduce a hidden state $h_t$:
The Loss Function
The RNN predicts $\hat{x}_{t+1}$ at each step. The loss measures prediction errors across the full sequence:
To minimize $\mathcal{L}$, we need $\frac{\partial \mathcal{L}}{\partial W_{hh}}$, $\frac{\partial \mathcal{L}}{\partial W_{xh}}$, and $\frac{\partial \mathcal{L}}{\partial W_{hy}}$. But $h_t$ depends on $h_{t-1}$, which depends on $h_{t-2}$, etc. We must unroll the network through time and apply the chain rule.
Backpropagation Through Time (BPTT)
Apply the chain rule step by step. Consider the gradient at time $t = 4$:
Vanishing Gradients: Interactive
The gradient magnitude at time step $k$ back scales as $\sim (\rho \cdot \overline{\tanh'})^k$:
LSTM: Solving the Vanishing Gradient
Hochreiter & Schmidhuber (1997) introduced gating mechanisms and a cell state highway:
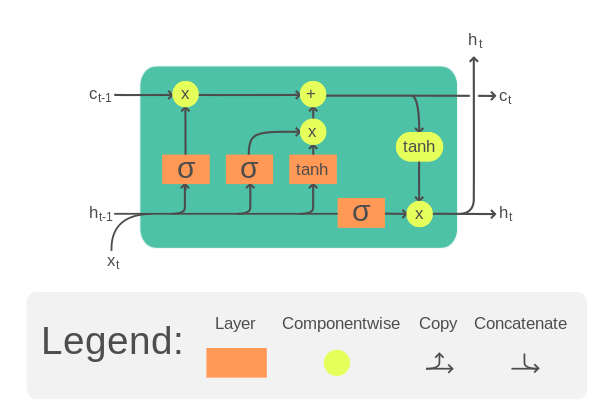
Source: Wikipedia — LSTM cell diagram
Part III: Reservoir Computing
What if you never train the recurrent weights?
Echo State Networks (Jaeger, 2001)
A radically different approach: the recurrent dynamics are random and fixed. Only a linear readout is trained.
$h_{t+1} = \tanh(W_{\text{in}} x_{t+1} + W h_t)$
Output (trained, linear):
$y_t = W_{\text{out}} h_t$
$W$ (reservoir $\rightarrow$ reservoir): random, fixed
$W_{\text{out}}$ (reservoir $\rightarrow$ output): trained via ridge regression
One linear solve. No backpropagation. Seconds, not hours.
The Echo State Property
For the reservoir to be useful, it must forget initial conditions:
$\|h(t) - h'(t)\| \to 0$ as $t \to \infty$
for any two initial states driven by the same input.
Sufficient condition: spectral radius $\rho(W) < 1$
(because $\tanh$ is Lipschitz-1, so $\|h_t - h'_t\| \leq \|W\| \cdot \|h_{t-1} - h'_{t-1}\|$)
Best performance at the boundary between order and chaos.
$\rho \ll 1$: short memory, strong nonlinearity
$\rho \to 1$: long memory, more linear
$\rho > 1$: risk of instability
Reservoir Dynamics: Interactive
Watch how reservoir neurons respond to a sinusoidal input at different spectral radii:
Memory Capacity: A Conservation Law
How much can a reservoir remember? (Dambre et al. 2012)
$MC = \sum_{k=1}^{\infty} r^2(W_{\text{out}} h_t, \; x_{t-k}) \leq N$
Total capacity (linear + nonlinear) $= N$
More computation $\Leftrightarrow$ less memory.
Each neuron contributes $\sim 1$ degree of freedom.
Physical Reservoir Computing
Any physical system with sufficient complexity, nonlinearity, and fading memory can be a reservoir:
| Physical System | Reservoir Mechanism | Reference |
|---|---|---|
| Photonic circuits | Mach-Zehnder modulator + delay feedback | Larger et al. 2012 |
| Mechanical networks | Mass-spring nonlinear coupling | Dion et al. 2018 |
| Quantum systems | Interacting qubits, exponential Hilbert space | Fujii & Nakajima 2017 |
| Biological neurons | Cortical microcircuits (Liquid State Machines) | Maass et al. 2002 |
Case Study: Predicting Chaos
Pathak et al., Physical Review Letters (2018)
The Kuramoto-Sivashinsky Equation
A model of spatiotemporal chaos, originally for flame-front instabilities (Kuramoto 1978, Sivashinsky 1977):
- $-u \, u_x$: nonlinear advection (energy transfer between scales)
- $-u_{xx}$: anti-diffusion (energy injection at small scales)
- $-u_{xxxx}$: hyper-diffusion (energy dissipation at smallest scales)
Simulated KS-like spatiotemporal pattern
Pathak et al.: Architecture & Results
| Reservoir size | $N = 5000$ neurons |
| Input | 64-dim spatial discretization |
| Training | Ridge regression only |
| Spectral radius | $\rho \approx 0.9$ |
| Prediction | Output fed back as input |
$\sim 8$ Lyapunov times of valid prediction
Correct Lyapunov spectrum
Accurate long-term climate (statistics)
All with ridge regression. No backpropagation.
Architecture Comparison
| Feature | Vanilla RNN | LSTM | ESN |
|---|---|---|---|
| Recurrent weights | Trained (BPTT) | Trained (BPTT) | Fixed random |
| Training cost | $O(N^2 T \cdot \text{epochs})$ | $O(N^2 T \cdot \text{epochs})$ | $O(N^2 T + N^3)$ |
| Gradient issues | Vanishing/exploding | Mitigated (cell highway) | None |
| Memory | Short | Long (gated) | $\leq N$ (hard limit) |
| Interpretability | Low | Low | High (linear readout) |
| Adaptability | Learned features | Learned features | Random features |
Beyond: Modern Extensions
ResNet: $h_{k+1} = h_k + f(h_k)$
As layers $\to \infty$: $\frac{dh}{dt} = f(h, t)$
Chen et al. 2018
Mamba: structured SSM
$h' = Ah + Bx$, $y = Ch$
Linear recurrence, $O(N \log N)$
Attention over full sequence
No explicit recurrence
Dominant in NLP
Gauthier et al. 2021
No reservoir: polynomial features
of time-delay embeddings
Cho et al. 2014
Simplified LSTM: 2 gates
Often comparable performance
Lim et al. 2021
Attention + LSTM hybrid
Multi-horizon forecasting
Summary: Design Principles
| Era | Architecture | Core Idea | Physics Connection |
|---|---|---|---|
| 1980s | Hopfield / Boltzmann | Energy minimization as computation | Ising model, stat mech |
| 1990s | RNN / LSTM | Learned dynamics in hidden space | Dynamical systems, state-space |
| 2000s | Echo State Networks | Random dynamics + linear readout | Edge of chaos, physical reservoirs |
| 2020s | Transformers / SSMs | Attention = Hopfield retrieval | Modern Hopfield energy |
References
Hopfield & Boltzmann
Hopfield (1982). Neural networks and physical systems with emergent collective computational abilities. PNAS.
Ramsauer et al. (2021). Hopfield networks is all you need. ICLR.
McEliece et al. (1987). The capacity of the Hopfield associative memory. IEEE TIT.
Hinton & Sejnowski (1983). Boltzmann machines. CVPR.
Hinton (2002). Contrastive divergence. Neural Computation.
Hinton et al. (2006). Deep belief nets. Neural Computation.
RNNs & LSTMs
Hochreiter & Schmidhuber (1997). Long short-term memory. Neural Computation.
Cho et al. (2014). GRU encoder-decoder. EMNLP.
Reservoir Computing
Jaeger (2001). Echo state networks. GMD Report 148.
Maass et al. (2002). Liquid state machines. Neural Computation.
Pathak et al. (2018). Predicting spatiotemporal chaos. PRL.
Dambre et al. (2012). Information processing capacity. Scientific Reports.
Gauthier et al. (2021). Next generation RC. Nature Comm.
Modern
Chen et al. (2018). Neural ODEs. NeurIPS.
LeCun et al. (2006). Energy-based learning. MIT Press.